
Domain-Weltkarte von United Domains
United Domains hat im Moment eine Aktion laufen:
Sie bieten eine Domain-Karte zum Kauf von 29 Euro an. Wenn man aber als Blogger – so wie ich hier zum Beispiel – in seinem Blog über die Karte und die Aktion schreibt, dann bekommt man diese Karte im Großformat 120x60cm für umme. Sozusagen gesponsertes virales Marketing… 🙂
Wie auch immer. Ich mache mit, denn so eine Karte macht sich sicher schick in meinem tollen neuen Büro in der neuen Wohnung… Sobald diese halt irgendwann mal gefunden sein mag… Hach je… Alles nicht so einfach 🙂
via netzhure.de
News im Web 2.0
Das „Web 2.0“ mit seinem User-Generierten Content hebt Nachrichten auf ein ganz neues Niveau. Noch nie kamen News schneller vom Ort des Geschehens in die Welt heraus.
Klar – dem ganzen fehlt bei „Schnellmeldungen“ dann insgesamt noch die Tiefe eines gut recherchierten Artikels, aber eine Kurzmeldung in einem Newsticker bietet die auch nicht.
Kevin Sablan hat sich mal die Mühe gemacht, das ganze am Beispiel des Flugzeugabsturzes in New York zu zeigen, indem er Meldungshäppchen von Twitter, Flickr, YouTube und Vimeo zusammengetragen hat: Hudson crash, lifestreamed by storytlr. Einfach auf das Bild des Flugzeugs im Wasser klicken, dann startet die Slideshow.
Es fängt mit Meldungen von Leuten direkt vor Ort an: „There’s a plane in the Hudson. I’m on the ferry going to pick up the people. Crazy.“, dann kommen immer mehr Details, wie etwa „plane from LaGuardia to Charlotte, NC“, „Airbus A320“ und erste Meldungen von schockierten Beobachtern „OMFG!!! a US Air flight just crashed right into the Hudson river right outside my apartment window!! NOW!“ und geht bis zur Info, wer der Pilot war, der die Katastrophe zum Unfall reduzieren konnte: „The hero of Flight 1549: The hero of Flight 1549 was pilot Chesley B. Sullenberger III. http://tinyurl.com/7w29ca“ und „It’s official: Chesley B. “Sully” Sullenberger, III is the new Chuck Norris“.
Nachrichten in einer neuen Dimension.
AFQQWZVTJTLPV
Ähm…
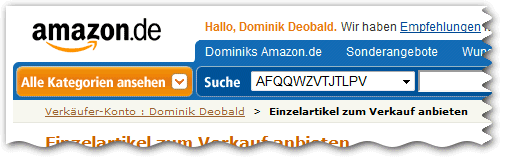
Was genau kann ich da durchsuchen?
(Inzwischen leider schon wieder weg. War nur ganz kurz sichtbar 🙂 )
Quergelesen 2009-01-14
Verschiedenes:
- 14.528 SMS in einem Monat
Die Empfänger dürften nicht schlecht gestaunt haben: Ein amerikanisches Mädchen hat ihren Eltern jüngst eine 440-seitige Telefonrechnung ihres Mobilfunkanbieters beschert – sie verschickte durchschnittlich 500 SMS pro Tag. Alleine im Monat Dezember waren es 14.528 Stück, die ihre Freundinnen insgesamt von ihr erhalten haben. (siehe auch NewYork Post)
Internet:
- Wie Umweltschädlich ist Googeln?
Wie viel Kohlendioxid wird durch Internetnutzung freigesetzt? Ein Harvard-Physiker sagt, durch den Besuch einer Website würden 20 Milligramm des Gases emittiert. Eine englische Zeitung behauptet gar: Zweimal googeln setzt so viel des schädlichen Gases frei wie einmal Tee kochen. Google bestreitet das. - Das Geheimnis der verschwundenen Bücher
Kunden des E-Book-Händlers Fictionwise werden ab Ende Januar keinen Zugriff mehr auf DRM-geschützte E-Books haben, die vom Distributor Overdrive geliefert wurden. Overdrive stellt die Server für die E-Books ab.
Games:
- Pädagogen kritisieren Kölner Aufruf der Spielekritiker
„Diese sogenannten ‚Spiele‘ sind in Wirklichkeit Simulationen der Kriegsrealität“ – so stand es Dezember 2008 in einem „Kölner Aufruf“ gegen Computerspiele. Jetzt übt ein Verband für Medienpädagogik heftige Kritik an den Kollegen. - US-Politiker fordert Warnung auf Spieleschachteln
„WARNUNG: Übermäßiger Umgang mit gewalthaltigen Computerspielen und anderen gewalthaltigen Medien gilt als Ursache für aggressives Verhalten“ – diese Warnung möchte ein Mitglied des amerikanischen Kongresses künftig auf Spieleverpackungen drucken lassen. (siehe auch betanews.com)
Fernsehen:
- «Grey’s Anatomy»: Solider Einstand in Runde 5 (@Nadine)
SF2 zeigt die fünfte Staffel von «Grey’s Anatomy» ab Montag, den 12. Januar 2008, immer um 21.40 Uhr. Wann die Serie in Deutschland startet, ist noch nicht klar.
Die Arbeit, die zu wenig Zeit einnimmt!!

Jaja, die Arbeit hätte ich gern…
„Verdammt, ich war viel zu schnell fertig…“
Sinnlosen Bot-Traffic vermeiden
Im WWW wimmelt es inzwischen ja nur so von verschiedenen Bots. Manche füttern Suchmaschinen, manche machen anderes. Manche sind sinnvoll für Webseiten-Betreiber, manche nicht.
Ich habe inzwischen angefangen, besonders sinnlose, störende oder sogar schädliche Spider auszusperren, die unsere Webseiten herunterladen wollen. Immerhin verbrauchen die unsere Bandbreite und unsere Rechenleistung, die wir an anderer Stelle besser einsetzen können.
Einige Bots sind ja noch so nett und schauen erst mal in die robots.txt, ob sie Daten abrufen dürfen. Andere greifen einfach zu. Und die allerschlimmsten sind die, die sich noch nicht mal als Bot identifizieren. Gegen die ist nicht so leicht anzukommen – denn man erkennt sie einfach nicht.
Ein paar von dieser Sorte sperre ich grundsätzlich in der .htaccess anhand der IP aus:
SetEnvIfNoCase Remote_Addr "^82.99.30." banned SetEnvIfNoCase Remote_Addr "^69.58.178." banned SetEnvIfNoCase Remote_Addr "^69.84.207." banned SetEnvIfNoCase Remote_Addr "^91.205.124." banned SetEnvIfNoCase Remote_Addr "^86.162.11.102" banned SetEnvIfNoCase Remote_Addr "^82.99.30." banned order allow,deny allow from all deny from env=banned
Das ist allerdings nur ein Tropfen auf den heißen Stein… Diese IPs sind sehr spezifisch und sind einfach ein paar, die mir negativ aufgefallen sind.
Bei den folgenden Bots / User Agents ist das einfacher. Damit diese Regeln funktionieren muss vorher mod_rewrite mit „RewriteEngine On“ eingeschaltet werden.
RewriteCond %{HTTP_USER_AGENT} ^BAGL/Nutch-0.9 [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Baiduspider [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^CCBot [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Java/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Microsoft\ URL\ Control [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Python-urllib [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^sonarv [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Touche [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Yanga [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^Yeti/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^BPImageWalker/ [OR,NC]
RewriteCond %[HTTP_USER_AGENT} ^QRVA [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*NaverBot/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*DBLBot/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*discobot/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*DotBot/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*MJ12bot/ [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*VoilaBot [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Pockey [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*NetMechanic [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*SuperBot [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebMiner [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebCopier [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Web\ Downloader [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebMirror [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Offline [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebZIP [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebReaper [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Anarchie [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Mass\ Down [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*BlackWidow [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebStripper [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*WebHook [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Scooter [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*swish-e [OR,NC]
RewriteCond %{HTTP_USER_AGENT} ^.*Teleport[NC]
RewriteRule ^.*$ - [F,L]
Was sperren diese Regeln aus?
- Eine Hand voll Tools, die komplette Webseiten herunterladen
Etwa Teleport oder WebReaper. Es gibt keinen wirklichen Sinn, das zu tun. Hier könnten und sollte eigentlich auch wget mit drin stehen, aber das verwenden wir stellenweise intern. - Diverse „Libraries“, die Programmierer verwenden können, um Webseiten abzurufen
Etwa Java, Python-urllib und Microsoft URL Control. Diese Libraries werden oft verwendet, um SPAM-Bots zu schreiben oder um Webseiten zu „rippen“, um sie auf dem eigenen Webserver mit eigener Werbung zu spiegeln. Natürlich wird auf diesem Weg nicht die Library selbst ausgesperrt, sondern nur die User, die sich mit den Standard-UserAgents identifizieren. Ähnlich wie oben wget wäre hier auch auf Wunsch noch cURL einzufügen. - Einige asiatische Suchmaschinen
Zum Beispiel Baidu oder Naver. Auf diesem Weg verhindern wir vielleicht, dass manche Personen uns finden, aber Asien gehört nicht wirklich zu unserer Zielgruppe. - Einige sinnlose Suchmaschinen
Das sind Suchmaschinen, die einfach (noch?) keine Relevanz haben oder die in unserer Zielgruppe keine Relevanz haben. Hier wären beispielsweise Yanga und Voila zu nennen. Stellenweise habe ich auch Cuil ausgesperrt (nicht in dieser Liste oben). In diesen Fällen steht die durch die Bots erzeugte Last auf unseren Servern in keiner Relation zu den auf diesem Weg erreichten Besuchern. Wenn beispielsweise ein Bot jeden Tag 1000 Dateien abruft, dann aber nur ein Besucher im Monat gebracht wird, dann macht das einfach keinen Sinn. - Einige komplett sinnlose Bots
Da zu nennen wären beispielsweise der MJ12bot und der CCBot. Die sammeln einfach nur Daten und behaupten, irgendwann mal was sinnvolles damit zu tun. Von Majestic12 gibt es immerhin inzwischen eine Alpha-Version von der Suchfunktion. Die Relevanz ist allerdings gleich null.
Etwas anders – der Vollständigkeit halber aber auch erwähnt – ist das hier:
RewriteRule wp-login\.php - [F,L] RewriteRule xmlrpc\.php - [F,L] RewriteRule wp-atom\.php - [F,L] RewriteRule login_page\.php$ - [F,L] RewriteRule include\.php$ - [F,L] RewriteRule php.*my.*admin - [NC,F,L] RewriteRule mysql - [NC,F,L] RewriteRule typo3 - [NC,F,L] RewriteRule xampp - [NC,F,L] RewriteRule w00tw00t - [F,L]
Damit sperre ich diverse URLs, die gerne von Hackern aufgerufen werden, die einfach mal schauen, was es für Angriffsflächen gibt, und beantworte sie mit 403 FORBIDDEN.
Eigentlich ziemlich sinnlos, denn die entsprechenden Dateien gibt’s auf den Servern ohnehin nicht – und wenn doch, dann will man sie normalerweise auch aufrufen können. Aber es werden auf diese Weise doch ein paar Bytes gespart, da die 403 FORBIDDEN Fehlermeldung im Normalfall kleiner ist als die 404 NOT FOUND Datei.
Außerdem sind 404 NOT FOUND Seiten oft auch irgendwie mit der Datenbank verknüpft. Die 403 FORBIDDEN Seite kann man einfach ausgeben, während man das 404 NOT FOUND in der Regel mit einer Hilfestellung für die User verbinden möchte. Hackern ist es in der Regel egal, ob sie einem den Server durch viele schnell aufeinander folgende Aufrufe lahmlegen. Von daher: einfach eine statische 403 FORBIDDEN Seite rausjagen. Das erzeugt nahezu keine Server-Last.
And last, but not least: Man kann dann in der Log-Datei die entsprechenden Aufrufe leichter identifizieren.
Google SafeSearch: Hahn ist böse, Penis ist gut
Fortschrittliche Filtertechniken setzt Google offensichtlich für SafeSearch ein. Was das ist?
Viele Google-Nutzer ziehen es vor, wenn nur jugendfreie Seiten in ihren Suchergebnissen aufgeführt werden. Dies trifft insbesondere dann zu, wenn Kinder denselben Computer verwenden. Google SafeSearch filtert Websites mit nicht-jugendfreiem Inhalt heraus und löscht diese aus Ihren Suchergebnissen. Kein Filter arbeitet mit 100-prozentiger Genauigkeit, allerdings wird das meiste unpassende Material durch SafeSearch entfernt.
Probier wir’s doch mal aus…
Sieht ja schon so aus, als ob es einigermaßen gehen würde… Weiter…
- cock – 0 Suchergebnisse… Moment… Darf man jetzt auch nichts mehr über Tiere erfahren? Ein cock ist doch ein Hahn…
- penis – über 30 Mio. Suchergebnisse… Aha… Clitoris ist böse, Hahn ist böse, Penis ist gut
Sehr fortschrittlich, liebe Googler… Eine Blacklist für Suchbegriffe – und dann auch noch eine nicht sehr vollständige…
If you want to delete your site from my spam list…
Habe gerade folgenden Beitrag im 4cheaters-Forum gefunden:
to: Admin – If You want to delete your site from my spam list, please visit this site for instructions: remove-url.co.cc
Also: JavaScript und Java ausgeschaltet und die Seite mal aufgerufen… Die Domain ist nicht (mehr?) registriert, so weit ich das sehen kann.
Aber: DAS ist doch schon zeimlich frech, oder? Und vermutlich ein Versuch, noch mehr SPAM-Adressen zu sammeln.
Wenn man bei Google nach „Admin – If You want to delete“ sucht, dann bekommt man gesagt, dass über 400.000 Seiten gefunden würden. Teilweise soll man Mails an verschiedene Mail-Adressen schicken, manchmal irgendwelche Webseiten besuchen.
Und ich bin sicher, danach gibt’s bestenfalls noch mehr SPAM…
Zwei Drittel weniger Spam
 So einfach kann’s sein… Da klemmt man einfach eine Colo vom Internet ab, und auf ein mal gibt’s 60% weniger SPAM-Mails im Netz…
So einfach kann’s sein… Da klemmt man einfach eine Colo vom Internet ab, und auf ein mal gibt’s 60% weniger SPAM-Mails im Netz…
Kaum hatte man dem Provider McColo am Dienstag den Saft abgedreht, schon konnte man einen Knick in den Grafiken sehen, die das SPAM-Volumen anzeigen.
Es wird zwar vermutet, dass die Spammer schnell eine neue Möglichkeit finden, um ihre Viagra-Pillchen unter’s Volk zu bringen – aber für die nächsten paar Tage könnte es etwas ruhiger bleiben…
Hoffen wir mal…
Mehr Infos: